|
|
|
This thread is locked; no one can reply to it.

|
| Good gosh, the new Rachet & looks like a PIXAR movie |
|
Chris Katko
Member #1,881
January 2002
 |
http://www.theverge.com/2015/6/10/8759787/ratchet-clank-ps4-first-trailer For those who don't know, Insomniac Games is headed by Mike Acton, a huge proponent of data-oriented design. Everything is packed into data streams, there is no object oriented-code in the engine, and "code is worthless/disposable". The guy is a genius, and not afraid of speaking at CPPCON and telling them he doesn't even like C++. And now, look what they've done with the PS4. CG movie-quality gameplay. -----sig: |
|
Mark Oates
Member #1,146
March 2001
 |
https://www.youtube.com/watch?v=rX0ItVEVjHc This guy's brilliant. He's speaking my language. -- |
|
Chris Katko
Member #1,881
January 2002
|
He basically echos and solidifies my thoughts about C++, but with much more experience and data to back it up. I mean, don't get me wrong, enterprise solutions have more important things to do than just performance, so OOP makes sense for things like GUIs. But treating everything in a video game like a particle system makes tons of sense. I absolutely loved his point at the end, some old guy asks "We're engineers at my firm, we just have to get it done. It doesn't matter how long it takes to run." And he replies, "Yeah, that's true. But you're also the reason it takes 15 seconds to load a Word document." It's kind of like: Why does Winamp take 9 MB of RAM and 0% CPU usage to play an MP3, while QMMP (a Linux Winamp clone) takes over 64 MB of RAM and at least a single digit CPU percentage. It's either API bloat (out of the control of the developers), or it's end developer bloat. "Organization for the sake of organization" according to Acton. Like how data oriented design tells you, "Just because you think of the world in terms of objects, a tree, a dog, etc. Doesn't mean it's efficient for computer has to represent them that way. When have you ever seen a two trees that looked identical? They aren't. So why would you assume a class can represent them?" -----sig: |
|
StevenVI
Member #562
July 2000
 |
Chris Katko said: When have you ever seen a two trees that looked identical? They aren't. So why would you assume a class can represent them? Either this is an obvious troll or is severely out of context. Surely nobody intelligent would propose that you should rewrite identical code for shared behaviors between similar entities. __________________________________________________ |
|
Chris Katko
Member #1,881
January 2002
|
StevenVI said: Either this is an obvious troll or is severely out of context. Surely nobody intelligent would propose that you should rewrite identical code for shared behaviors between similar entities. Well, to be fair, I'm probably remembering it wrong. I couldn't find the exact article I read it on. -----sig: |
|
bamccaig
Member #7,536
July 2006
 |
I don't get the whole "looks like a PIXAR movie" reference. I don't see how it's in any way special compared to any other game of its type... I don't have time to watch the video right now, but perhaps I'll get a chance tonight. Based on Google research the idea is an emphasis on optimization over design purity/normalization/simplicity. In other words, for things that should be fast, like games, or very common, rarely changing things like loading a document structure, it makes sense to optimize the code in this way. Whereas, for many tasks that software developers in the world work on the costs of this level of optimization outweigh the benefits. Of course, "OOP" is generally understood to be something of a law of nature instead of merely a tool in your kit. It's obvious for a beginner to become obsessed with OOP before having wrapped their heads around it, but it isn't really the holy grail of design. I personally find that it's better to have data grouped together into dumb data structures and have the logic separate. It might still make sense to have the data structures and service code each encapsulated by an "object", but it's distinct from most people's naive idea of "OOP" whereby a "ball" has a "bounce" method, etc. I think that most people's idea of OOP is fundamentally broken from day one by naive examples. Most people's solution doesn't represent the world accurately at all. A ball doesn't bounce. A ball has physical attributes, and the physical laws of the universe act upon it over time to achieve what we call a "bounce". A ball bounces, but a ball doesn't bounce itself. A person doesn't even jump. A person manipulates limbs which interact with the world through physical laws of the universe acting upon them. In the end, you always have these high-level physical laws making just about everything we understand (or fail to understand) about the universe happen. It translates to the business world just as well. A credit card doesn't charge itself. An order doesn't submit itself. There are always external forces acting upon these things, often gluing them together as interactions.
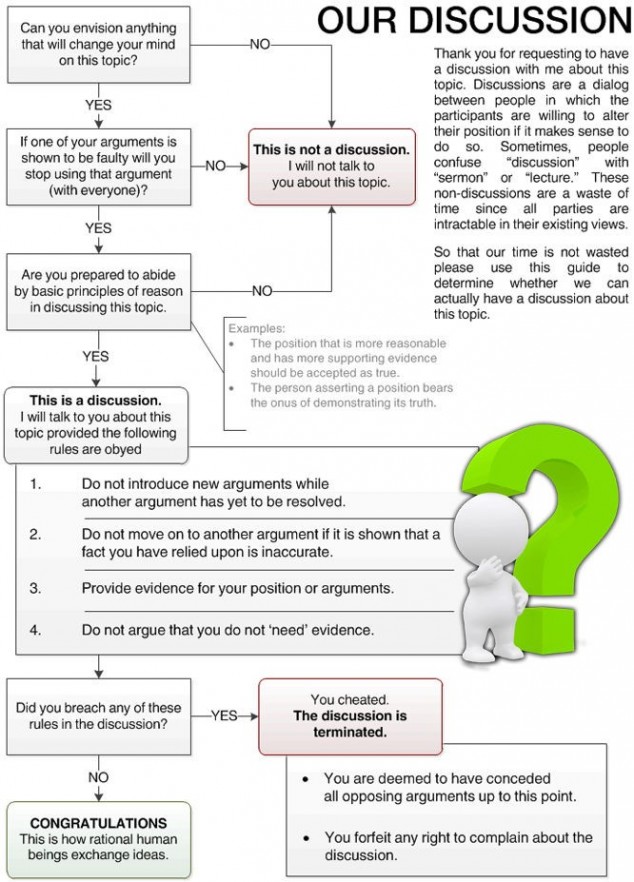
-- acc.js | al4anim - Allegro 4 Animation library | Allegro 5 VS/NuGet Guide | Allegro.cc Mockup | Allegro.cc <code> Tag | Allegro 4 Timer Example (w/ Semaphores) | Allegro 5 "Winpkg" (MSVC readme) | Bambot | Blog | C++ STL Container Flowchart | Castopulence Software | Check Return Values | Derail? | Is This A Discussion? Flow Chart | Filesystem Hierarchy Standard | Clean Code Talks - Global State and Singletons | How To Use Header Files | GNU/Linux (Debian, Fedora, Gentoo) | rot (rot13, rot47, rotN) | Streaming |
|
Mark Oates
Member #1,146
March 2001
|
Chris Katko said: "Organization for the sake of organization" according to Acton. Like how data oriented design tells you, "Just because you think of the world in terms of objects, a tree, a dog, etc. Doesn't mean it's efficient for computer has to represent them that way. When have you ever seen a two trees that looked identical? They aren't. So why would you assume a class can represent them?" Acton is taking the antithesis of a position that I have had for a long time, which is that computers are (or should be) designed for humans to use. Acton's position seems to be that the human should solve the problem for the computer. I agree with him 100% that fundamentally, programming is about converting data from one format to another. Every part of the process, at every step. The purpose for doing the conversion is so that the new data format is optimized for a certain use. The evolution of languages, compilers, data formats, APIs, frameworks, etc, has always been a battle between either converting data for the computer to use, or converting data for the human mind to use. I've also come to a conclusion recently about C++ as a language, which is that it's more of a platform than I had realized. Acton's sentiments seem to have put words to my observations. Recently, I made a webserver using boost/asio, and while traversing all of the namespaces and helper objects, I began to get a sense that I was steeped in a methodology (objects/models/inheritance), which was ironically what I was trying to get away from in the first place (I've been using Ruby/Rails lately. Ruby is clearly an extra layer over C, and Rails is a whole 900-things on top of that). I had always thought that C++ as a language was somewhat agnostic, somewhat free from the stink of all of that. But it's just another layer, like all other layers in the stack. I want to learn Assembly now. I also liked the old Earlang programmer's quote which outlined another thing I've come to realize; From one language to the next, one version to the next, one framework after another, we're revisiting the same problem, but this time from a different perspective. Many times we're adding more layers on top of the next without even realizing that they're only marginally different and often don't offer much advantages to the other. I mean, we're making stuff that compiles to JavaScript. How crazy is that? I've also felt this same sense having moved away from MSVC towards gcc/vim/make. I feel like whole layers of abstraction have been removed (project folders, anyone?) and it gives me a strange sense of liberation. For web projects, I don't want to waste my time with a poorly designed web dashboard that "enables" me to setup some predefined databases. Just give me a blank-slate server with SSH root access I'll get what I need. -- |
|
Chris Katko
Member #1,881
January 2002
|
Here's another good one: https://www.youtube.com/watch?v=SI_GKdFQmds I don't recall which video he mentioned a quick-and-dirty technique for checking branch prediction is to output the values of the branch to a file, and then zip it. The amount of compression ratio will tell you how often it's changing too rapidly. Unfortunately, I don't recall the specifics. Those console guys are also all about sorting data. You sort data instead of branching on it. That way, a branch predictor only has to fail on the boundaries of those data changes. They're also about "pre-conditioning data" built straight into the asset pipeline so the program can make more assumptions. They use floating point circles instead of radians, so 0.5 is a half of a circle, so you can just chop off the whole number part and know where you are on the circle. Here's another article by him on eliminating branching using math at the expensive of portability: http://cellperformance.beyond3d.com/articles/2006/04/benefits-to-branch-elimination.html Sony has lots of material and videos on this kind of stuff (he's makes games for Playstations, especially the cell processor, so that makes sense). Like this one: Pitfalls of OO programming: -----sig: |
|
Polybios
Member #12,293
October 2010
|
In my experience, when working with super-cool-new-layer/tool XYZ long enough, you usually get to the point that you want to do something that could be very simple and straightforward. But then you notice it just doesn't fit well with the generalizing abstractions that were made. The super-cool new tool / layer starts to get in your way instead of propelling you forward. Then you have to write lots of horrible bloat-code to work around the assumptions that were obviously made although it seemed to be a "general" solution at first glance. That's why I tend to like low level tools like Allegro. |
|
bamccaig
Member #7,536
July 2006
|
Polybios said:
In my experience, when working with super-cool-new-layer/tool XYZ long enough, you usually get to the point that you want to do something that could be very simple and straightforward. But then you notice it just doesn't fit well with the generalizing abstractions that were made. The super-cool new tool / layer starts to get in your way instead of propelling you forward. Then you have to write lots of horrible bloat-code to work around the assumptions that were obviously made although it seemed to be a "general" solution at first glance. That's why I tend to like low level tools like Allegro. Absolutely. It's especially a problem with proprietary/closed-source software. With free software at worst you can patch it. With non-free software you are forced to work around it. You repeatedly run into this on Microsoft's software stacks. They're designed to do something simple simply, and anything non-trivial is completely impossible or completely hard/ugly/unmaintainable. It makes absolutely no sense. I'm convinced the only reason people use it is because they're incompetent and ignorant (or their manager is). -- acc.js | al4anim - Allegro 4 Animation library | Allegro 5 VS/NuGet Guide | Allegro.cc Mockup | Allegro.cc <code> Tag | Allegro 4 Timer Example (w/ Semaphores) | Allegro 5 "Winpkg" (MSVC readme) | Bambot | Blog | C++ STL Container Flowchart | Castopulence Software | Check Return Values | Derail? | Is This A Discussion? Flow Chart | Filesystem Hierarchy Standard | Clean Code Talks - Global State and Singletons | How To Use Header Files | GNU/Linux (Debian, Fedora, Gentoo) | rot (rot13, rot47, rotN) | Streaming |
|
beoran
Member #12,636
March 2011
|
Great presentation. He explains well the reasons that drive me to use pure C. |
|
|
 The gameplay footage looked normal. Not at all exceptional. Define "like a PIXAR movie" and qualify it with other games that don't share the same quality.
The gameplay footage looked normal. Not at all exceptional. Define "like a PIXAR movie" and qualify it with other games that don't share the same quality.

{kind=link}
{kind=link}