|
|
|
This thread is locked; no one can reply to it.

|
| [alguichan] widget frames |
|
tobing
Member #5,213
November 2004
 |
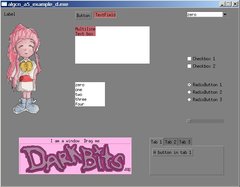
In guichan (and hence also in alguichan) there is a concept of frames around a widget. I'm not completely happy with this... So, what is a frame? Essentially it's something drawn around a widget, which is more or less a rectangular area with content. It serves to give the impression of a 3D-effect, like showing the widget somewhat deeper than the rest of the screen. There are two problems with this. One is, the frame is outside the widget itself, so it looks strange when widgets are close together. The other is, depending on what you want to see, some widgets should have a frame (like a button or a window), other should not (like a label or a checkbox). Then there are widgets (like listbox) that should have a frame in some places, but not in others. Of course each widget can have an individual setting of frame size, so there might be no problem at all. I'm thinking about the defaults however, introducing the concept of a style into alguichan, and that's where I want to have reasonable defaults that don't need much tweaking aside from setting values in the style object. Is there any need for frames at all? If so, how can I specify which widgets should have a frame (with given size) with only a few numbers in the style object? Here's the usual test program, showing almost all widgets, with all frames 0: And here's the same with frame size 1 for 'buttons' and 'areas': Note that the TextField and the DropDown seems to have a frame in the first image, but that's a border, like the border of the Button. This border is inside the widget, and it doesn't look completely consistent, given that most other widgets don't have a border. So next question is, should all widgets (or at least most of them) have a border? |
|
Mark Oates
Member #1,146
March 2001
 |
Those buttons are nayasty In my quest to skin my gui, I've collected a few images of UIs that have a generally nice and unimposing appearance. I have attached a bunch. My latest iteration is drawn using only allegro primitives: -- |
|
X-G
Member #856
December 2000
 |
I'm not sure I'd call that pink-and-gold monstrosity "unimposing"... -- |
|
Mark Oates
Member #1,146
March 2001
|
You are correct. In that one, the yellow glow follows the mouse staying along the bottom (clipped with al_clip_whatever) and "pink-and-golds" on hover only. Like the win button: -- |
|
Matthew Leverton
Supreme Loser
January 1999
 |
Graphically, yes, things should generally have borders. This is how I decided to implement it for my GUI:
So I leave it up to the theme manager to decide how to do the border. My included theme has no concept of customizable borders. E.g., the button widget draws its border as part of the inner clipped contents. The only widget so far that has a true border is the frame (window) widget. It overloads the resize method and resizes the inner clipped rectangle to the request size. Thus a algui_resize(window, 640, 480) creates a window with an inner width of 640x480. For a widget with a border (e.g., a framed window), the theme would set the dimensions of the inner clipped rectangle. Then all of its widgets are drawn accordingly to that rectangle. If somebody really wants to add borders to all items without redrawing all of the built-in widgets, my response is simply to create your own BORDER_WIDGET container and add things to it. e.g.: void add_with_border(void *parent, void *child, int width) { BORDER_WIDGET *border = create_border(width); algui_add(border, child); algui_add(parent, border); } BUTTON *button = algui_create_button("Foo Bar"); add_with_border(desktop, button, 2); So now you get a border wrapped around your object. Of course if the object already has a border, you'd get a double border. But, again, I consider this something that the theme creator gets to decide. Personally, I didn't want to bother creating widgets with borders that both look good and can be modified, so I hardcoded them into the widget. |
|
Mark Oates
Member #1,146
March 2001
|
Matthew, I'm curious, have you considered menu dropdowns that show outside of the current display, eg this, when a window is at the edge of the screen? Perhaps as a separate frameless display (though frameless displays are not completely supported across platforms)? -- |
|
Matthew Leverton
Supreme Loser
January 1999
|
Yes, the theme manager has a "place object" function it can override. By default it simply places the object at x,y on its parent. But it could then draw a shadow outside that on the parent's canvas. That's the tentative plan anyway. I'm currently using that approach to draw shadows on framed windows. Note that I implement both framed windows and pop-up menus as null-rooted components. So they aren't constrained to the apparent root desktop widget in any way. That is you may have:
(Any component can be null-rooted, although most commonly you'd have a desktop widget.) Clicking the button creates the window, which is rooted at the display area. Now if that button were sitting on a corner and had a shadow that spilled outside the 320x240 bounds of its desktop, it wouldn't get drawn due to clipping. (Unless the theme manager cheated, and drew directly to the display buffer.) But the window, as it sits outside of the desktop's constraints, can easily have a shadow drawn outside of its main canvas area without having to "cheat." |
|
Mark Oates
Member #1,146
March 2001
|
But all of this takes place within the application's window, correct? I'm asking specifically about dropdowns outside the program's window itself, inside the OS. -- |
|
Matthew Leverton
Supreme Loser
January 1999
|
Yes, by "display" in my list above, I mean an ALLEGRO_DISPLAY. You can also create native windows (their own ALLEGRO_DISPLAY), but on those it's up to the OS to draw the frame and shadow. |
|
Mark Oates
Member #1,146
March 2001
|
Hm.. I don't follow. Here's a picture using a different example. In this case, it's necessary for the dropdown menu to extend beyond the confines of the application-which-contains-the-gui's window, so it would (theoretically) create a separate ALLEGRO_DISPLAY for the list dropdown. -- |
|
Thomas Fjellstrom
Member #476
June 2000
 |
I wouldn't bother setting up a separate OS window for drop downs inside an allegro app. -- |
|
Mark Oates
Member #1,146
March 2001
|
Thomas Fjellstrom said: I wouldn't bother setting up a separate OS window for drop downs inside an allegro app. I only ask because in Matthew's 3rd(?) algui video he shows a dialogue where a native dialogue window still retains as an extension of the underlying algui (a separate display with algui widgets, I'm assuming, as opposed to one of the native dialogues). It seems like a "pop-out" dropdown would be a consistent next step. [edit] here. -- |
|
Thomas Fjellstrom
Member #476
June 2000
|
Mark Oates said: It seems like a "pop-out" dropdown would be a consistent next step. But creating a new ALLEGRO_DISPLAY for that is a bit heavy handed. Especially on linux and OpenGL where it has to do a lot of work when creating a new display. -- |
|
tobing
Member #5,213
November 2004
|
When I look at it, doing something like a theme (manager) or styles right is more difficult and complicated than I want to deal with now. So I think for me it's probably best to keep it as simple as possible for the time being. I'll think about these things though, and continue to make changes here and there. Thanks for all your input and thought! |
|
Matthew Leverton
Supreme Loser
January 1999
|
Thomas Fjellstrom said: I wouldn't bother setting up a separate OS window for drop downs inside an allegro app. I don't. The only time I use a separate OS window is if the user requests one. The point of that video was to show that internally you can treat the widget as if it were drawn by algui. Regarding pop-up menus, there could be some problems with clipping. I don't intend to solve the core one of not being able to draw outside of the ALLEGRO_DISPLAY area.* I will work around it by moving the dialog up/left such that you can see it. (Just like your OS would do if you tried to pop up a menu near the bottom of the desktop.) What I was getting at earlier is that you don't have to worry about internal clipping issues with popup menus. Say you have:
The window, if owned by the desktop widget, is constrained to the 200x200 area. However, if you click on its menu bar and a menu item pops up, it is not constrained to the 100x50 area. Neither is it constrained to the 200x200 desktop widget, because it gets created as a stand alone component with full access to the 640x480 display. But it cannot draw beyond those constraints. So in your screenshot, take the yellow outline and shove it up such that the bottom of it is aligned with the bottom of the cyan outline. * Disclaimer: At least, I wouldn't try to solve it before the first released version. tobing said: When I look at it, doing something like a theme (manager) or styles right is more difficult and complicated than I want to deal with now If you can strike the right balance, it's not too hard. But I would definitely be sure to have a good plan before starting, because it's not stuff you want to just hack in. |
|
jmasterx
Member #11,410
October 2009
|
Mark Oates said: My latest iteration is drawn using only allegro primitives: Could I see the code you used to draw these with Allegro primitives? Thanks Agui GUI API -> https://github.com/jmasterx/Agui |
|
Thomas Fjellstrom
Member #476
June 2000
|
Matthew Leverton said: Regarding pop-up menus, there could be some problems with clipping. If you use the border-less flag on a ALLEGRO_DISPLAY, there shouldn't be any clipping issues, you'd get a top level window with no border or title bar to do with as you see fit. -- |
|
Mark Oates
Member #1,146
March 2001
|
jmasterx said: Could I see the code you used to draw these with Allegro primitives? Sure! Here's the first button ( void ui_button_default_draw(void *obj, void *user) { UIButton *b = static_cast<UIButton *>(obj); al_draw_filled_rounded_rectangle(b->x+0.5, b->y+0.5, b->x+b->w+0.5, b->y+b->h+0.5, b->roundness, b->roundness, b->background_color); al_draw_rounded_rectangle(b->x+0.5, b->y+0.5, b->x+b->w+0.5, b->y+b->h+0.5, b->roundness, b->roundness, b->border_color, 1.0); al_draw_rounded_rectangle(b->x+0.5+1, b->y+0.5+1, b->x+b->w+0.5-1, b->y+b->h+0.5-1, b->roundness, b->roundness, b->inner_border_color, 1.0); al_draw_filled_rectangle(b->x+3.5, b->y+3.5, b->x+b->w-3.5, b->y+b->h/2, b->hilight_color); if (b->font) al_draw_text(b->font, b->text_color, b->x+b->w/2+b->label_displacement_x, b->y+b->h/2-al_get_font_ascent(b->font)/2+b->label_displacement_y, ALLEGRO_ALIGN_CENTRE, b->label.c_str()); if (b->click_in) al_draw_rounded_rectangle(b->x+0.5+1, b->y+0.5+1, b->x+b->w+0.5-1, b->y+b->h+0.5-1, b->roundness, b->roundness, al_color_name("yellow"), 1.0); }
The last one... uses a bitmap for the glow, apparently ( 1ALLEGRO_BITMAP *button_hilight;
2float button_hilight_opacity;
3float button_hilight_x;
4
5void ui_glowing_button_draw_func(void *obj, void *user)
6{
7 UIButton *b = static_cast<UIButton *>(obj);
8 al_draw_filled_rounded_rectangle(b->x+0.5, b->y+0.5, b->x+b->w+0.5, b->y+b->h+0.5, b->roundness, b->roundness, b->background_color);
9
10 if (b->mouse_over())
11 {
12 int x, y, w, h;
13 al_get_clipping_rectangle(&x, &y, &w, &h);
14 al_set_clipping_rectangle(b->x+1, b->y+1, b->w-2, b->h-2);
15 button_hilight_opacity = 0.3;
16
17 al_set_blender(ALLEGRO_ADD, ALLEGRO_ONE, ALLEGRO_ONE);
18
19 al_draw_tinted_bitmap(button_hilight,
20 al_map_rgba_f(button_hilight_opacity, button_hilight_opacity, button_hilight_opacity, button_hilight_opacity),
21 button_hilight_x-al_get_bitmap_width(button_hilight)/2, b->y+b->h-al_get_bitmap_height(button_hilight), NULL);
22
23 al_set_blender(ALLEGRO_ADD, ALLEGRO_ONE, ALLEGRO_INVERSE_ALPHA);
24
25 al_set_clipping_rectangle(x, y, w, h);
26 }
27
28 al_draw_rounded_rectangle(b->x+0.5, b->y+0.5, b->x+b->w+0.5, b->y+b->h+0.5, b->roundness, b->roundness, b->border_color, 1.0);
29 al_draw_rounded_rectangle(b->x+0.5+1, b->y+0.5+1, b->x+b->w+0.5-1, b->y+b->h+0.5-1, b->roundness, b->roundness, b->inner_border_color, 1.0);
30
31 al_draw_filled_rectangle(b->x+3.5, b->y+3.5, b->x+b->w-3.5, b->y+b->h/2, b->hilight_color);
32
33 if (b->font) al_draw_text(b->font, b->text_color,
34 b->x+b->w/2+b->label_displacement_x, b->y+b->h/2-al_get_font_ascent(b->font)/2+b->label_displacement_y,
35 ALLEGRO_ALIGN_CENTRE, b->label.c_str());
36}
The second button requires a soft gradient, drawn onto a bitmap and overlayed on the button. Ahnd, here's the HSlider ({"name":"603427","src":"\/\/djungxnpq2nug.cloudfront.net\/image\/cache\/f\/9\/f9fdd1ebc28a8b83d87153d536e43690.png","w":248,"h":34,"tn":"\/\/djungxnpq2nug.cloudfront.net\/image\/cache\/f\/9\/f9fdd1ebc28a8b83d87153d536e43690"} 1void ui_hslider_default_draw(void *obj, void *user)
2{
3 UIHSlider *slider = static_cast<UIHSlider *>(obj);
4
5 al_draw_filled_rounded_rectangle(slider->x, slider->y, slider->x+slider->w, slider->y+slider->h,
6 5, 5, al_color_html("f9f9f9"));
7 al_draw_rounded_rectangle(slider->x+0.5, slider->y+0.5, slider->x+slider->w+0.5, slider->y+slider->h+0.5,
8 5, 5, al_color_html("f0f0f0"), 1.0);
9
10 float radius = 6.5;
11
12 al_draw_filled_rectangle(slider->x+slider->axis_padding, slider->y+slider->h/2-2,
13 slider->x+slider->w-slider->axis_padding, slider->y+slider->h/2+2,
14 al_color_name("lightgrey"));
15
16 al_draw_rectangle(slider->x+0.5, slider->y+0.5+slider->h/2-2,
17 slider->x+0.5+slider->w, slider->y+0.5+slider->h/2+2,
18 al_color_html("f7f7f7"), 1.0);
19
20 float circle_center = slider->x+slider->axis_padding+(slider->w-slider->axis_padding*2)*slider->val;
21 al_draw_filled_circle(circle_center, slider->y+slider->h/2, radius, al_color_html("629f4a")); //f7f7f7
22
23 ALLEGRO_COLOR hilight_color = al_map_rgba_f(0.6, 0.6, 0.6, 0.6);
24 ALLEGRO_COLOR border_color = al_color_html("4e8638");
25
26 al_draw_filled_rectangle(slider->x+3.5, slider->y+3.5, slider->x+slider->w-3.5, slider->y+slider->h/2, hilight_color);
27
28 al_draw_circle(circle_center, slider->y+slider->h/2, radius-1, al_color_html("87bf70"), 1.0);
29 al_draw_circle(circle_center, slider->y+slider->h/2, radius, border_color, 1.0);
30}
-- |
|
Matthew Leverton
Supreme Loser
January 1999
|
Thomas Fjellstrom said: If you use the border-less flag on a ALLEGRO_DISPLAY, there shouldn't be any clipping issues, you'd get a top level window with no border or title bar to do with as you see fit. Right. In the part you quoted, I was referring to clipping issues caused by not using a separate ALLEGRO_DISPLAY. @Mark, time to create your own integer based line and rectangle drawing functions. Sure beats adding the +0.5 and trying to remember the rules. |
|
Mark Oates
Member #1,146
March 2001
|
Matthew Leverton said: @Mark, time to create your own integer based line and rectangle drawing functions. {"name":"603429","src":"\/\/djungxnpq2nug.cloudfront.net\/image\/cache\/b\/4\/b48fb1dba9a419bec3fa6f55d99bbe7c.png","w":448,"h":104,"tn":"\/\/djungxnpq2nug.cloudfront.net\/image\/cache\/b\/4\/b48fb1dba9a419bec3fa6f55d99bbe7c"} -- |
|
Trezker
Member #1,739
December 2001
 |
In my GUI there's only one widget size, the one that the container widgets work with. How the size is handled by containers vary. I haven't put margin support in anywhere yet, but I think that should be handled in the containers , not the regular widgets. If a widget should have a frame that goes outside its own area, I think I'd create a container with one child that has a view which renders the frame and the child, it would request a size that holds the childs requested size and the frames size. That way I could frame anything from a single widget to a whole sublayout. |
|
Mark Oates
Member #1,146
March 2001
|
Trezker said: I haven't put margin support in anywhere yet, but I think that should be handled in the containers , not the regular widgets. agreed. For me, the widget's coordinates and width/height are also the bounding boxes for mouse_over mouse_out events. So if you want padding, move the widget. -- |
|
Matthew Leverton
Supreme Loser
January 1999
|
Trezker said: That way I could frame anything from a single widget to a whole sublayout. Other than my framed windows, that's how my GUI works. (And I may ultimately change framed windows to act the same way.) Margins are set by the layout manager. e.g.: tabs = algui_create_tab_panel(); algui_set_tab_panel_margins(tabs, 16, 16, 16, 16); algui_add_to_tab_panel(tabs, "Tab 1", algui_create_button("Foo")); algui_add_to_tab_panel(tabs, "Tab 2", algui_create_button("Bar")); The tab panel widget is composed of an implicit vbox container with a tab strip on the top and an empty stretched slot in the bottom (for the user's widget). Setting the tab panel margin actually sets the margin of the bottom slot of its vbox container: // in the tab panel code algui_set_layout_margins(this->vbox, /*index*/ 1, n, e, s, w); The default tab widget draws its own outer border. If you want inner borders, you'd have to create some sort of border frame widget and add things to it. |
|
|