|
|
|
This thread is locked; no one can reply to it.

|
| Performance of function pointers, ifs and switch statements. |
|
Gnamra
Member #12,503
January 2011
 |
I wanted to compare the three mentioned in the title, and this is the result I got: Pointers: 4.09492s I find it a bit odd that they're this close in time. In the for loop with the function pointer it doesn't have to do any checks, it just does the calculation to get the index and then calls the function, right? The reason I'm curious is because I'm toying with the idea of making a small game using hopefully no if statements. It may be a stupid idea, but I got it when thinking about the fact that in the real world there aren't any checks, it's all cause and effect and I want to try to make a program that works in the same way. I'd very much like it if anyone could provide some information on why they're so close in terms of performance, and why the switch is faster than using function pointers? Here's the code which I used to time them. 1#include <iostream>
2#include <stdio.h>
3#include <chrono>
4#include <cstdlib>
5#include <ctime>
6#define LOOPAMOUNT 10000000000
7
8int one();
9int two();
10int three();
11int four();
12int five();
13int six();
14int seven();
15int eight();
16int nine();
17int ten();
18
19int (*p[10]) (void);
20
21int main(void)
22{
23 p[0] = one;
24 p[1] = two;
25 p[2] = three;
26 p[3] = four;
27 p[4] = five;
28 p[5] = six;
29 p[6] = seven;
30 p[7] = eight;
31 p[8] = nine;
32 p[9] = ten;
33
34 std::chrono::time_point<std::chrono::high_resolution_clock> start, start2, start3, end, end2, end3;
35
36 // Using function pointers
37 start = std::chrono::high_resolution_clock::now();
38 for(unsigned long long i = 0; i < LOOPAMOUNT; i++)
39 {
40 (*p[i % 10]) ();
41 }
42 end = std::chrono::high_resolution_clock::now();
43
44 // Using if statements
45 start2 = std::chrono::high_resolution_clock::now();
46 for(unsigned long long i = 0; i < LOOPAMOUNT; i++)
47 {
48 if(i % 10 == 0) one();
49 else if(i % 10 == 1) two();
50 else if(i % 10 == 2) three();
51 else if(i % 10 == 3) four();
52 else if(i % 10 == 4) five();
53 else if(i % 10 == 5) six();
54 else if(i % 10 == 6) seven();
55 else if(i % 10 == 7) eight();
56 else if(i % 10 == 8) nine();
57 else ten();
58 }
59 end2 = std::chrono::high_resolution_clock::now();
60
61 // Using switch
62 start3 = std::chrono::high_resolution_clock::now();
63 for(unsigned long long i = 0; i < LOOPAMOUNT; i++)
64 {
65 switch(i % 10)
66 {
67 case 0: one(); break;
68 case 1: two(); break;
69 case 2: three(); break;
70 case 3: four(); break;
71 case 4: five(); break;
72 case 5: six(); break;
73 case 6: seven(); break;
74 case 7: eight(); break;
75 case 8: nine(); break;
76 case 9: ten(); break;
77 }
78 }
79
80 end3 = std::chrono::high_resolution_clock::now();
81
82 std::chrono::duration<double> elapsed_seconds = end - start;
83 std::chrono::duration<double> elapsed_seconds2 = end2 - start2;
84 std::chrono::duration<double> elapsed_seconds3 = end3 - start3;
85
86 std::cout << "Pointers: " << elapsed_seconds.count() << "s\n";
87 std::cout << "Ifs: " << elapsed_seconds2.count() << "s\n";
88 std::cout << "Switch: " << elapsed_seconds3.count() << "s\n";
89
90 system("pause");
91 return 0;
92}
93
94int one()
95{
96 return 1;
97}
98
99int two()
100{
101 return 2;
102}
103
104int three()
105{
106 return 3;
107}
108
109int four()
110{
111 return 4;
112}
113
114int five()
115{
116 return 5;
117}
118
119int six()
120{
121 return 6;
122}
123
124int seven()
125{
126 return 7;
127}
128
129int eight()
130{
131 return 8;
132}
133
134int nine()
135{
136 return 9;
137}
138
139int ten()
140{
141 return 10;
142}
|
|
#00JMP00
Member #14,740
November 2012
|
Looking at the code, I find it strange why you would use modulo. You could simplify things by using for(0...10), couldn't you? But maybe this is only the prototype for something bigger, which will At second glance, why don't you need & to asign function pointers to the functions?? p[n] = &one...and so forth. Last issue: Why do you set up functions 2 to n, when you only test function 0 and 1. |
|
Gnamra
Member #12,503
January 2011
|
I'm using modulo to get a number from 0 to 9 I could use 0 to 9, but by looping through so many times the differences add up and it becomes more clear how each one performs compared to the others. p[n] = one is just the short form of doing it. Not using & depends on the compiler, but you should use & if you want to write portable code. I didn't care about it since this was just a small program to find out how the different approaches to call a bunch of functions compared to each other. But I removed the short array of size 10, because it was redundant. I used it for something before just changed it without realizing how redundant it was. What do you mean by set up function 2 to n? When I checked, all the different functions are being called.
|
|
#00JMP00
Member #14,740
November 2012
|
Gnamra said: I'm using modulo to get a number from 0 to 9 You are right, I am wrong. I thought you would use num[i]%10 to call the functions, but you use a different value. Therefore everything is fine :-) Actually all numbers 0 to 9 %10 will turn out to be 0, not even 1. Therefore the test is maybe not correct. You should assign at least numbers to 100 to num[i] to get a result. 1
2 for(int i = 0; i < 10 0; i++) // change this, to get better result
3
4 num[i] = i;
|
|
Gnamra
Member #12,503
January 2011
|
No, 0 - 9 % 10 will give 0-9. When it hits 10, then 10 % 10 will give 0. Because of this i % 10 will give 0-9 over and over again. Also I removed the num[i], the array was redundant, I could just do i % 10 instead. I'll edit the code.
|
|
Chris Katko
Member #1,881
January 2002
 |
If you want to make a game without "if"s then, you're going to quickly be overwhelmed, but feel free to try it. Remember, a game isn't the real world. It's a simulation... an approximation. And every time you approximate something, imagine you're putting a nice piecewise function together with an if statement. That being said: 1 - Look at the assembly, and for the love of God turn off optimizations. For all you know all of those turn into the same code. 2 - If/switch/etc are all the same anyway. It's a thousand times worse to incur a context switch than it is to use any branching. So what you're getting is a CPU with a gigantic "velocity" but a tiny "acceleration" and every time you decide to switch contexts it has to stop and start the process over again. So there are things entirely out of your control (like task scheduling) that will have more effect on your program than your decision for using switches/ifs/etc in most cases. 3 - Never assume a benchmark reflects real-world performance. -----sig: |
|
torhu
Member #2,727
September 2002
 |
Benchmarking without optimizations isn't that useful, I'd say compile with -O2, but move the function definitions into a separate file to make sure they are not inlined. Add up all the return values and print the result in the end to make sure the calls are not removed by the optimizer. It's also a good idea to change the order of the items you are benchmarking to make sure the order does not affect performance. Putting each test into its own function makes this easier. The reason switches can be faster than ifs is that they are often optimized into jump tables, meaning there are no comparisons, only one table lookup and one or two unconditional jumps. But this could in principle happen to a series of ifs too, looking at the assembly is the best way to tell. By the way, you need some way to select which functions to call anyway, so you might end up reinventing switch statements somehow |
|
bamccaig
Member #7,536
July 2006
 |
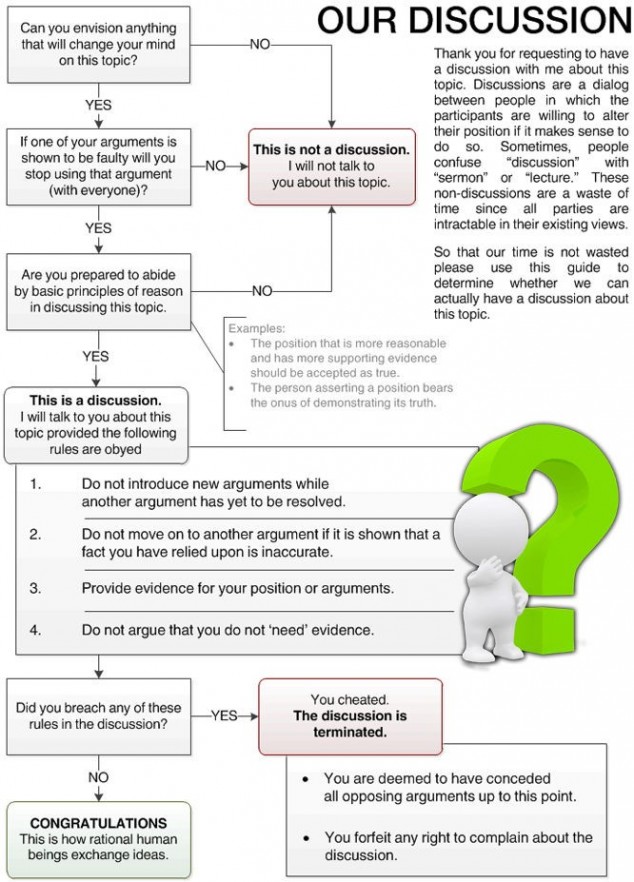
I can't figure out what it is that you're trying to benchmark here. -- acc.js | al4anim - Allegro 4 Animation library | Allegro 5 VS/NuGet Guide | Allegro.cc Mockup | Allegro.cc <code> Tag | Allegro 4 Timer Example (w/ Semaphores) | Allegro 5 "Winpkg" (MSVC readme) | Bambot | Blog | C++ STL Container Flowchart | Castopulence Software | Check Return Values | Derail? | Is This A Discussion? Flow Chart | Filesystem Hierarchy Standard | Clean Code Talks - Global State and Singletons | How To Use Header Files | GNU/Linux (Debian, Fedora, Gentoo) | rot (rot13, rot47, rotN) | Streaming |
|
torhu
Member #2,727
September 2002
|
Don't listen to bamccaig, he has forgotton what curiosity is |
|
bamccaig
Member #7,536
July 2006
|
Benchmarking without a real world example is useless. 99% of the time if you make a guess about what is wrong with your program that is causing it to be so slow you will be wrong (at least until you have 10 or 20 years of experience under your belt and have already been wrong enough to know). Generally the only reliable way to speed a program up these days is to run it through a profiler and let the profiler tell you where all of the time is spent. Computers have gotten exponentially more complicated than they were 20 years ago. There may have been a time when this question was a valid one to ask, but these days it isn't really... It's a waste of the OP's time, IMO, and it's irresponsible to encourage it instead of pointing him in a more appropriate direction... -- acc.js | al4anim - Allegro 4 Animation library | Allegro 5 VS/NuGet Guide | Allegro.cc Mockup | Allegro.cc <code> Tag | Allegro 4 Timer Example (w/ Semaphores) | Allegro 5 "Winpkg" (MSVC readme) | Bambot | Blog | C++ STL Container Flowchart | Castopulence Software | Check Return Values | Derail? | Is This A Discussion? Flow Chart | Filesystem Hierarchy Standard | Clean Code Talks - Global State and Singletons | How To Use Header Files | GNU/Linux (Debian, Fedora, Gentoo) | rot (rot13, rot47, rotN) | Streaming |
|
Audric
Member #907
January 2001
|
torhu said: move the function definitions into a separate file to make sure they are not inlined No, some optimizations can be performed at link time, so these functions can still be inline. It's not so easy to outsmart a compiler ! I'm with bamccaig on this one : It's totally naive to try optimize if you don't have a general idea of what matters. |
|
torhu
Member #2,727
September 2002
|
Audric said: No, some optimizations can be performed at link time, so these functions can still be inline. It's not so easy to outsmart a compiler ! Sure, but enabling link-time optimization when you want to avoid inlining functions defined in other files would a bit be silly, don't you think? |
|
Audric
Member #907
January 2001
|
Ah sorry, I took this statement out of context. You were advising -O2 so you're talking explicitely of GCC, and indeed, it will not perform LTO unless you request it explicitely using -flto |
|
Chris Katko
Member #1,881
January 2002
|
I'm all for curiosity, however, optimization should be the last step, not the first one. A program that works slowly gets shipped. A program that goes fast and doesn't do anything doesn't... and in five years a slow program runs fast on new computers. (e.g. Adobe Photoshop) -----sig: |
|
relpatseht
Member #5,034
September 2004
 |
Hello Gnarma, To expand on what Chris and torhu were saying, let me see if I can answer your questions succinctly. Gnamra said: I find it a bit odd that they're this close in time. In the for loop with the function pointer it doesn't have to do any checks, it just does the calculation to get the index and then calls the function, right?
Quote: I'd very much like it if anyone could provide some information on why they're so close in terms of performance, and why the switch is faster than using function pointers? Correct, the CPU doesn't have to do any checks, but have you ever noticed how CPU clock speeds (GHz) have remained steady for quite a while now while our processing power has improved? That is because of things like pipelining and branch prediction. If this were the VERY old days, your switch statement would be one or two jumps, followed by one jump to the function, while your function pointer being just a jump to the function, but that isn't true anymore. With the switch statement, the CPU has already predicted what function it is going to be calling, loaded it, and started it's execution before the function is ever called. With the function pointers, it is having a more difficult time predicting which pointer that function pointer if going to direct to, thus incurring some delay. I'm not sure if you have any optimization turned on or not. If not, I would say the slowest part of your if statement is the repeated modulo operator, not the comparison.
|
|
Gnamra
Member #12,503
January 2011
|
Thanks for all of the feedback! But it seems like some of you assume that I have a bottleneck in my code, but there is no code except what I posted in the first post. I thought I made it clear. I wrote that code just to see how fast each of the different ways of determining what function to run was. I thought that feeding an index to an array of function pointers would be the fastest, I did it with and without optimizations and I found that in this particular case on my machine the switch was fastest. This makes sense to me now because you lovely people explained to me how compilers can use a jump list. I was under the impression that it would check from top to bottom in the switch and with the ifs. I wrote the above code purely out of curiosity, and I'm pleased to see the results and all the feedback I got, thank you guys! My thinking was that if I had each of the different ways of determining what function to run in a loop, the differences in performance between them would add up and it would be more clear which one was fastest. What I gathered from the results and what I've read in this thread is that there isn't any major performance difference, and that in fact the compiler could be doing the same thing with all of the three approaches. I also know that the results I got only apply to my machine, I did try to do this on a couple of different machines I got a bit different results but on most of them the switch was the fastest. I'd like to repeat that I did this purely out of curiosity, most of the things I do are out of curiosity, I love reinventing the wheel, it gives me a deeper understanding of how it works and why it works. Sorry if this post is a bit messy, I was in a bit of a hurry when writing it. But thanks guys, I really appreciate it!
|
|
Arthur Kalliokoski
Second in Command
February 2005
 |
Gnamra said: But it seems like some of you assume that I have a bottleneck in my code They all watch too much MSNBC... they get ideas. |
|
Gnamra
Member #12,503
January 2011
|
Oh, ok I see what you mean now.
|
|
Chris Katko
Member #1,881
January 2002
|
And my additional point from the other thread: The standard strategy is write code clearly and only optimize what the profiler tells you is taking all your time. The only (rare) time that strategy fails is: http://c2.com/cgi/wiki?UniformlySlowCode Which either occurs after many useful iterations of Profile + Optimize, or because a very new programmer does something very very silly. Quote: Example: In C++, passing objects to all functions by value, and returning by value can worsen UniformlySlowCode due to the constant construction and destruction of temporary objects. Example: QuakeGame by IdSoftware, compiled using Acorn C on the ARM600. Quake uses float for everything. The ARM CPU has no FPU. All floating point is emulated by the OS via the compiler. Which is a different problem altogether, and is the correct time to really look into options like modifying the structure of data and functions. -----sig: |
|
|

 None of these code constructs should be the bottleneck in your code, but even if they were, I don't think that your tests would accurately measure their performance. It's also the kind of thing that doesn't have a single right answer. What might be right on your hardware for a simple test might be wrong on your hardware with a real world situation, or even on my hardware with the same simple test. Don't waste your time with this kind of thing unless you have a lot of it and plan to focus your career on low-level optimization (generally not very worthwhile in 99% of applications, but there are some unique systems where it is vital and you could find employment working with those if you learn your stuff...). For the most part, I can't help thinking "why would you even?"
None of these code constructs should be the bottleneck in your code, but even if they were, I don't think that your tests would accurately measure their performance. It's also the kind of thing that doesn't have a single right answer. What might be right on your hardware for a simple test might be wrong on your hardware with a real world situation, or even on my hardware with the same simple test. Don't waste your time with this kind of thing unless you have a lot of it and plan to focus your career on low-level optimization (generally not very worthwhile in 99% of applications, but there are some unique systems where it is vital and you could find employment working with those if you learn your stuff...). For the most part, I can't help thinking "why would you even?" 


{kind=link}
{kind=link}