|
|
|
This thread is locked; no one can reply to it.

|
1
2
|
| How hard is this problem for you to solve? |
|
Chris Katko
Member #1,881
January 2002
 |
I do not claim to be a "code fu" kind of guy. I don't do Code Golf for fun in my spare time. This problem showed up last week at work and I was surprised at the difficulty of wrapping my head around the code implementation of it. You have a data table of: - 3 columns of data. with sample data (in my case it was some 20,000 rows): 100, 232, "Shipping" It's seemingly simple. "Deduplicate any rows where the first two columns match, where data takes precedence over blanks." But the second you start writing code, now you have to deal with how you're looping through it and whether you're modifying the data structure en-loop or creating a new one. It was a fun puzzle in the few hours I had to get it working at the end of one work shift. Knowing you guys, there's probably some jerk that can do it in two lines of Haskell. -----sig: |
|
torhu
Member #2,727
September 2002
 |
Maybe I'm slow, but I don't understand why this is hard... Python has a CSV reader module, and it has hash maps |
|
pkrcel
Member #14,001
February 2012
|
Might be it was not actually CSV, and there were other constraints? Problem sounds and probably IS simple but implementation of the de-duplicating algorithm may be a bit tricky (haven't thought really about it, honestly). What was exactly the culprit of your "struggle"? It is unlikely that Google shares your distaste for capitalism. - Derezo |
|
torhu
Member #2,727
September 2002
|
Yeah, could be too little information. If it's actually like the example data, you could easily do it in Python by using a dict with tuples of the values from the first two rows as the keys, and a set of values from the third row as the value. Problem solved. |
|
Chris Katko
Member #1,881
January 2002
|
Well, perhaps I was too worn out by the end of the day. Python is great, I've really started to learn and love it the last few weeks. But I'm still new to it. You can use "set" to unique-ify lists. But it's only going to work over the entire tuple. Can you unique based on only a subset of data, and yet have it effect the whole? My "struggle" was, each time I tried to implement my idea, I would run into boundries. Use dictionaries? Ok, but you can't index a dictionary. Use lists? Enjoy n^2 iteration and you still can't modify the container inside a traditional for each. So now, you have to be able to decide whether or not each entry should go into the new list (it's unique), or not (it's a duplicate), but not send the same unique value twice. Or, modify the list as you index it manually, compare each against all the other entries, and when a duplicate is found run the comparison to see who "wins" and remove the loser. See what I'm getting at? The issue is deceptively simple, the implementation is not--at least to my inexperienced brain. -----sig: |
|
Matthew Leverton
Supreme Loser
January 1999
 |
Delete t1 from tbl t1, tbl t2 where t1.id = t2.id and t2.type <> '' and t1.type = '' Sitting in an airport with my phone. |
|
pkrcel
Member #14,001
February 2012
|
Chris Katko said: See what I'm getting at? The issue is deceptively simple, the implementation is not --at least to my inexperienced brain. Exactly what I thought , implementation may be tricky. One thing that I was worried about in my (very) sparse thoughts was not find the duplicates (even caching the results in an ad-hoc index, and then modifying the whole structure at once), but doing the thing INTELLIGENTLY with a non-exponential O loop, for example. My perplexity was due to the fact that you worded the problem as there was some sort of n"hidden gotcha". Anyway I am thinking language agnostic, and Matthew example (which I get is SQL? ) shows that "implementation" is ALSO a matter of tools. BTW, was it implied that you were using Python? I do not have any knowledge of it It is unlikely that Google shares your distaste for capitalism. - Derezo |
|
Chris Katko
Member #1,881
January 2002
|
My experience is C++ and some C#. Python is recent, but it's insanely fun and easy. Like 90% of it is "How do you do X... oh my gosh, it's that easy?" Matt: It was already in CSV so I don't think SQL was the answer. But that's still pretty amazing. pkrcel said: One thing that I was worried about in my (very) sparse thoughts was not find the duplicates (even caching the results in an ad-hoc index, and then modifying the whole structure at once), but doing the thing INTELLIGENTLY with a non-exponential O loop, for example. Yeah, my first try literally scanned everything against everything and it was slowwww. Then I made sure that all "deduplicated" entries were at "the top" of the list and started the scan after that. It worked fast enough for a work script. -----sig: |
|
bamccaig
Member #7,536
July 2006
 |
Perl example: 1###
2### Disclaimer: Assumes that AddressType != "" only exists
3### once per (CompanyID,AddressID) pair.
4###
5### i.e., No actual merging is attempted, just removes
6### 'invalid' rows.
7###
8### * Nitpick: Assumes the file encodings are UTF-8 compatible.
9### Accommodating alternative encodings is left as an exercise
10### for the reader.
11###
12
13use autodie;
14use strict;
15use warnings;
16
17use Text::CSV;
18
19my @columns = qw/CompanyID AddressID AddressType/;
20
21if (@ARGV != 2 || $ARGV[0] =~ /^-/) {
22 print STDERR <<EOF;
23Usage: $0 IN_CSV OUT_CSV
24
25The IN_CSV file is expected to have no header row and @{[scalar @columns]} columns:
26
27@{[join ', ', @columns]}
28
29The OUT_CSV format is arbitrarily defined by the Text::CSV module.
30EOF
31 exit 1;
32}
33
34my $csv = Text::CSV->new({ allow_whitespace => 1, binary => 1 });
35
36$csv->column_names(@columns);
37
38my ($in_path, $out_path) = @ARGV;
39
40open my $in_fh, '< :encoding(utf-8)', $in_path;
41open my $out_fh, '> :encoding(utf-8)', $out_path;
42
43while (my $row = $csv->getline_hr($in_fh)) {
44 if ($row->{AddressType} ne "") {
45 $csv->print($out_fh, [@{$row}{@columns}]);
46 print $out_fh "\n";
47 }
48}
49
50$csv->eof() or $csv->error_diag();
51
52close $in_fh;
53close $out_fh;
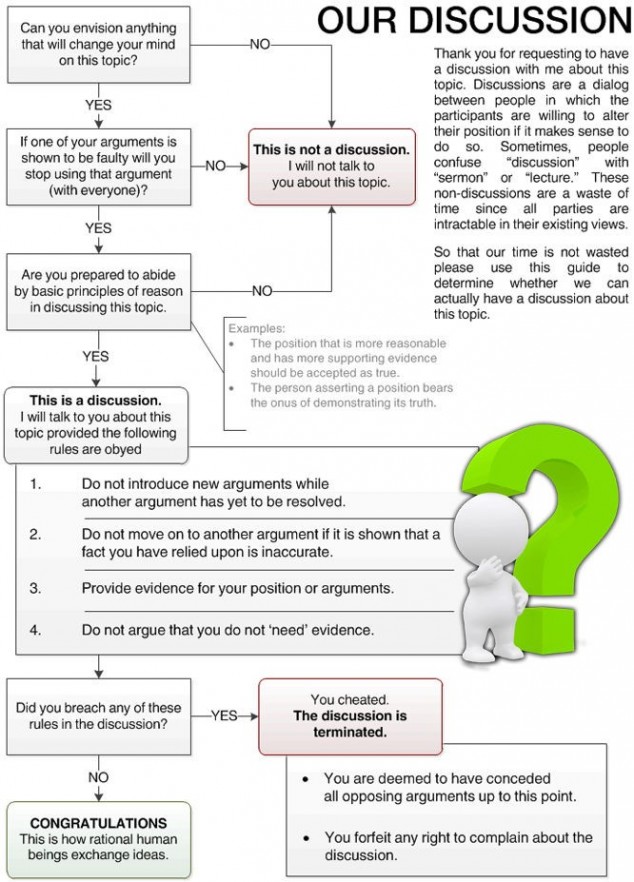
That's no golf example, but it gets the job done. That took me about 3 minutes to stub out, and another 30 minutes to debug. That is with a little (rusty) experience parsing and processing CSV with Perl. I used a module somewhat new to me (Text::CSV) which resulted in most of the debugging time, but I'm also rusty with the module that I'm more familiar with (Text::CSV::Simple) so there's no guarantee that it wouldn't have taken me as long using that. The key to solving a problem like this "fast" is having done it before and having tools available to you that do most of the work for you. You should prefer a tool that lets you solve the problem quickly first. For this a dynamic programming language is ideal. Attempting to solve this well in C would add to the headache. As far as performance is concerned, 20000 rows is negligible. If you were dealing with gigabytes of data my solution would probably fall on its face (in particularly, it is needlessly copying data into new array structures, which could be eliminated with relatively little effort). Whether you go for something lazy and slow or something intricate and blazing depends on how much time you and the computer have to solve the problem, and also how much time it will take to develop and debug that blazing fast solution versus just letting the computer brute force with something sloppy. These kinds of problems can be deceptively time consuming. The more experience you have solving them the more quickly you'll wire the pieces up to solve them. Matthew might not have been entirely in left field. You might be able to get that data into a DBMS, run the query, and output it again more efficiently (human and machine) than rolling your own. For example, on our ancient QNX systems at work we are running an old version of Sybase ... Like 5.5 or something. I'm barely familiar with it, and documentation is hard to come by, but you can import CSV data with `INPUT INTO tbl FROM /path/to/csv;` and export data to CSV with `SELECT ...; OUTPUT TO /path/to/csv;`. That might well be an efficient way to solve the problem, but of course it depends on what kind of environments are available to you already (e.g., do you have a DBMS that supports importing/exporting CSV data, does one exist in a development or testing environment where an accidental query won't damage production data and cause downtime or loss, etc?). Another thing to note is that "CSV" is a poorly standardized format. Different software solutions understand different variations of it. You'll note that my Perl program doesn't output in the exact same "format" e.g., same rules as the input came from. You can almost certainly tweak the output somewhat, but there will be limitations. Generally when it comes to general parsing solutions they try to be strict with their inputs (one of the things that took time to debug was figuring out which configuration options were needed to parse your sample input; more may be needed for the real thing). General CSV parsers maybe struggle to support arbitrarily structured formats (e.g., quotes only for 'string typed' fields, etc.). A "well-formed" CSV format may be defined as no arbitrary white-space, always or never quoted fields, etc. All of these little details add to the complexity of the solution. Having your data in CSV is probably an indication of a problem to begin with. -- acc.js | al4anim - Allegro 4 Animation library | Allegro 5 VS/NuGet Guide | Allegro.cc Mockup | Allegro.cc <code> Tag | Allegro 4 Timer Example (w/ Semaphores) | Allegro 5 "Winpkg" (MSVC readme) | Bambot | Blog | C++ STL Container Flowchart | Castopulence Software | Check Return Values | Derail? | Is This A Discussion? Flow Chart | Filesystem Hierarchy Standard | Clean Code Talks - Global State and Singletons | How To Use Header Files | GNU/Linux (Debian, Fedora, Gentoo) | rot (rot13, rot47, rotN) | Streaming |
|
Chris Katko
Member #1,881
January 2002
|
bamccaig said: Another thing to note is that "CSV" is a poorly standardized format. Different software solutions understand different variations of it. You'll note that my Perl program doesn't output in the exact same "format" e.g., same rules as the input came from. You can almost certainly tweak the output somewhat, but there will be limitations. Generally when it comes to general parsing solutions they try to be strict with their inputs (one of the things that took time to debug was figuring out which configuration options were needed to parse your sample input; more may be needed for the real thing). General CSV parsers maybe struggle to support arbitrarily structured formats (e.g., quotes only for 'string typed' fields, etc.). A "well-formed" CSV format may be defined as no arbitrary white-space, always or never quoted fields, etc. All of these little details add to the complexity of the solution. Having your data in CSV is probably an indication of a problem to begin with.
Trust me, you do not one to see where I've been in the last two months with regards to CSV, XML, and Excel files in a data migration for a company. Sage CRM packs entire e-mails, including HTML ones into single entries of TEXT in SQL. Not BLOB/CLOB. Not external files. Single text entries. Moreover, we've got 300 tables of data, some with up to 300 columns. Excel is a natural choice, eh? Nope. Excel can't do more than 255 columns, and can't do more than 16KB in an entry. It technically can, if you turn on "big mode" but you'd be hard pressed to find an exporter that supports that. HTML tags and non-printable ASCII also confuse the hell out of it and crash it. XML? XML in XML, that'll work great. CSV? Oh wait, too bad we've got newlines. Let's use pipes to denote columns! Too bad Excel and Microsoft Dynamics don't. Start over. And even if you manage to export it, Microsoft Access OLEDB only scans the first 8 rows by default to decide the format. Have a column with 10 blanks and then phone numbers? Congratulations, all phone numbers are now ints. And those ones with hypens? We'll just cast them to blank text "" and not flag an error. All you have to do to fix that? Change a registry key... that is after the hours you wasted tracking the problem to Microsoft. But wait, there's more. Magically, as of today, my master C# converter program that takes 12 minutes to chug through over hundreds of thousands of lookups and symbolic links and post-process all their junk data (floating point numbers for phone numbers? Phone number extensions in people's last names?), all a sudden today it just stopped working. Phone numbers are trashed (the same way before we fixed the registry) and yet the registry settings are still the same. Windows Update, perhaps? Who knows! Meanwhile, even when we can use Excel, guess what! Microsoft Dynamics CRM 2013 runs on 64-bit. So you load the Importer/Export SQL Wizard and export Excel files. 2003 Excel, or 2007? We'll, you're running 64-bit Wizard, so try 2007. Okay, done. Give it to Dynamics. Too bad! Dynamics only supports 2003 and earlier Excel and XML files. Okay, flip the wizard and try it on 2003 Excel! Nope! 64-bit systems cannot run Microsoft Jet, which outputs 2003 Excel files, only Microsoft Access which can only output 2007 Excel files. Because I sure love batch converting files every time I need to re-export them! Let's keep going! Importing "notes" into Dynamics CRM is a charm! They even have an XML template for you to use! Oh wait, too bad. Even though there's a column for setting the owner of a note specifically in the XML, it won't read it. It'll set everyone's notes to you, the importer's account. How sweet, the client will love it. The solution? Oh that's easy, all you have to do is install the entire Dynamics CRM SDK, produce a signed DLL plugin, attach it to the running database, and all it does is set the fields that Microsoft hasn't bothered to fix since before 2009, there's almost no documentation for plugins, all Stack Overflow posts just say "read the docs" and the only guy with a tutorial has an incomplete "code snippet" to solve the problem all the way back in 2009. Whoopie! CRM is also now crashing, even on the client's end. Want an error code? Too bad, there are none. Turn on stack traces by hacking values in the registry! The answer is in the file, let's read it: "General error." I guess you're getting at how little programming I get to do at work. Quote: Having your data in CSV is probably an indication of a problem to begin with. The problem I'm having is called Microsoft. Which I never had any problem with until I had to use Windows 8 on my work computers (99% CPU usage on Superfetch, YAY!) and deal with Dynamics CRM which is nothing but a pretty "metro" interface on top of a giant heaping pile of hacks. Lastly, hmm, I seem to have taken myself off-topic. -----sig: |
|
bamccaig
Member #7,536
July 2006
|
Personally I wouldn't use Microsoft Office for anything programming related unless forced to. Though in general I won't use Microsoft Office for anything unless forced to. That more or less extends to Microsoft anything too. It's just not robust software. You end up attempting to link proprietary software with proprietary software. Sorry, only the most simple or standard configurations are supported or documented. Your real world case is either not supported or not documented and you don't know which. In my experience it's usually a waste of time trying. That isn't limited to Microsoft. I find all proprietary software is like that. Software is meant to be malleable. That's where the "soft" comes from. Proprietary software is not malleable. It might as well be hardware. It doesn't do exactly what you want, and you practically have to reverse engineer it to figure out what it can do. That's not to say that open source software solves all of life's problems, but it causes fewer of them and once you solve the ones you have you have the freedom to save the next guy the trouble. I think that as software developers the whole "capitalism" thing really doesn't work so well for most of us (for those few Bill Gates' it works out pretty fantastic, but those are a needle in a hay stack). Well I feel your pain. Maybe not the same pains, but similar ones. I think that Microsoft causes pain right across the board. Even our "in house" software feels proprietary. It often comes from Argentina, Mexico, or <elsewhere>. Often it is half Spanish/half English. When there even is source code there are no comments, and the code is not self documenting. Often there is no code. Only binaries from unknown sources. When there is code there are 100 copies of it and no record of its origins (i.e., production versions, incomplete updates, untracked "backups" in the event that updates cause irreversible damage; arbitrarily located and named). The majority of my job is debugging others' broken, undocumented, untracked code; or attempting to extend or change it with as few pokes as necessary and absolutely no development/test environments and usually a dearth of required development tools' software licenses.
-- acc.js | al4anim - Allegro 4 Animation library | Allegro 5 VS/NuGet Guide | Allegro.cc Mockup | Allegro.cc <code> Tag | Allegro 4 Timer Example (w/ Semaphores) | Allegro 5 "Winpkg" (MSVC readme) | Bambot | Blog | C++ STL Container Flowchart | Castopulence Software | Check Return Values | Derail? | Is This A Discussion? Flow Chart | Filesystem Hierarchy Standard | Clean Code Talks - Global State and Singletons | How To Use Header Files | GNU/Linux (Debian, Fedora, Gentoo) | rot (rot13, rot47, rotN) | Streaming |
|
torhu
Member #2,727
September 2002
|
Chris Katko said: You can use "set" to unique-ify lists. But it's only going to work over the entire tuple. Can you unique based on only a subset of data, and yet have it effect the whole? I was thinking of something like this: And if you subclass one of the built-in types and customize the comparison operators, you can do almost anything you like. If you need indexing, that's more complicated. But there's an OrderedDict class if that helps. |
|
Peter Hull
Member #1,136
March 2001
|
Example in Python: 1#!/usr/bin/python
2
3import csv
4
5entries = dict()
6
7with open('input.csv') as csvfile:
8 rdr = csv.reader(csvfile)
9 for row in rdr:
10 custid = row[0]
11 addrid = row[1]
12 typeid = row[2]
13 key = (custid, addrid)
14 if key in entries:
15 entries[key].add(typeid)
16 else:
17 entries[key] = set([typeid])
18
19with open('output.csv','wb') as csvfile:
20 wrt = csv.writer(csvfile)
21 for (key, value) in entries.iteritems():
22 if len(value) > 1:
23 value.discard('')
24 for t in value:
25 wrt.writerow([key[0], key[1], t])
N.B. it doesn't work with the dialect of CSV you've posted, I believe that all is required is to fiddle with the options on the csv.reader constructor.
|
|
Thomas Fjellstrom
Member #476
June 2000
 |
Maybe I missed it, but why not just export the data direct from whatever database the data was stored in using actual code? Was it not in MSQL? If not, why not ot: Text::CSV can handle just about any format you throw at it, including embedded newlines, and escaped column separation characters. -- |
|
Audric
Member #907
January 2001
|
Sorry if I miss something obvious, but I'd sort first on all three columns (the last one in descending order), and then I'd perform a single pass on all records, comparing record N with record N+1 : The specific process would be slightly complicated by the need sometimes to omit multiple records, but I guess it would stay O(N) |
|
Thomas Fjellstrom
Member #476
June 2000
|
Audric said: The specific process would be slightly complicated by the need sometimes to omit multiple records, but I guess it would stay O(N) I think you could safely restart the loop at the current location when it omitted an element, so it can recheck with the one after. -- |
|
bamccaig
Member #7,536
July 2006
|
Peter Hull said: Example in Python:
Is your 25 lines supposed to scare me?! 1use Text::CSV;
2
3my $csv = Text::CSV->new({ allow_whitespace => 1, binary => 1 });
4
5open my $in_fh, '< :encoding(utf-8)', 'input.csv';
6open my $out_fh, '> :encoding(utf-8)', 'output.csv';
7
8while (my $row = $csv->getline($in_fh)) {
9 if ($row->[2] ne "") {
10 $csv->print($out_fh, $row);
11 print $out_fh "\n";
12 }
13}
14
15$csv->eof() or $csv->error_diag();
And Text::CSV has an XS (native-code implementation) module so if you install that you can get C-like performance automatically (but see its caveats). Thomas Fjellstrom said: ot: Text::CSV can handle just about any format you throw at it, including embedded newlines, and escaped column separation characters. Yes, input is the easy thing to handle. CSV parsers can relax the rules quite a bit to do a best effort at parsing pretty horrible formats. However, the more relaxed the rules get the less reliable the parsing will get. I'm not at all surprised that Perl modules will parse almost anything you throw at them. Configuring for sloppy output is the harder job to do. It's all well and good if Perl can read the input, but if the programmers' own tools can't read the output then it doesn't do you any good to have generated the output. Therein lies the conundrum with using CSV at all. In particular, often propretary software will tell you it can generate or consume CSV without specifying exactly what that means. You are left to guess and the robustness of your solution depends on the accuracy of your assumptions. -- acc.js | al4anim - Allegro 4 Animation library | Allegro 5 VS/NuGet Guide | Allegro.cc Mockup | Allegro.cc <code> Tag | Allegro 4 Timer Example (w/ Semaphores) | Allegro 5 "Winpkg" (MSVC readme) | Bambot | Blog | C++ STL Container Flowchart | Castopulence Software | Check Return Values | Derail? | Is This A Discussion? Flow Chart | Filesystem Hierarchy Standard | Clean Code Talks - Global State and Singletons | How To Use Header Files | GNU/Linux (Debian, Fedora, Gentoo) | rot (rot13, rot47, rotN) | Streaming |
|
Peter Hull
Member #1,136
March 2001
|
bamccaig: you win. Let's leave it there. Any programming language X vs Y discussion gives off a scent which can be detected miles away by Haskellers. They glide out of their lairs and beat you to death with a Kleisli Arrow in the functor category of monoid transducers. Or something. Actually we are probably safe. I guess Peter Wang is the only one here smart enough to be using Haskell. Does Peter Wang use Haskell? Anyway, last comment on the subject: Pete
|
|
bamccaig
Member #7,536
July 2006
|
Protip: Tobias Dammers loves Haskell and could probably put forth a challenge, though if he can beat Perl at being terse I want to see it. -- acc.js | al4anim - Allegro 4 Animation library | Allegro 5 VS/NuGet Guide | Allegro.cc Mockup | Allegro.cc <code> Tag | Allegro 4 Timer Example (w/ Semaphores) | Allegro 5 "Winpkg" (MSVC readme) | Bambot | Blog | C++ STL Container Flowchart | Castopulence Software | Check Return Values | Derail? | Is This A Discussion? Flow Chart | Filesystem Hierarchy Standard | Clean Code Talks - Global State and Singletons | How To Use Header Files | GNU/Linux (Debian, Fedora, Gentoo) | rot (rot13, rot47, rotN) | Streaming |
|
Chris Katko
Member #1,881
January 2002
|
Peter Hull said:
Anyway, last comment on the subject: Wow, I've already encountered and had to deal with almost every point in that blog. Those points really aren't that bad to deal with (once you smash into and then finally understand them!) if you're doing it for a specific application, as opposed to a general-use library parser. As long as you can open up the relevant CSV's in a text editor, you can quickly deduce what the encoding is. The biggest problem with CSV, is that the morons that designed the code pages never bothered to leave a few characters specifically for delimiting data. If say, ASCII 17/18/19, meant "general purpose use" or "end of row/column", you'd be fine. -----sig: |
|
Peter Hull
Member #1,136
March 2001
|
Chris Katko said: The biggest problem with CSV, is that the morons that designed the code pages never bothered to leave a few characters specifically for delimiting data. If say, ASCII 17/18/19, meant "general purpose use" or "end of row/column", you'd be fine.
They did, 0x1c - 0x1f are set aside as separators for exactly this purpose.
|
|
bamccaig
Member #7,536
July 2006
|
What happens when the data itself contains embedded "records"? Now you need to embed them within records recursively! The same problems would arise regardless of the code points. Code points are ultimately just bytes. The key to defining any general purpose format is using exceptions and escapes to allow for the use of any syntactic constructs within the data, and to tell them apart reliably. The point is TIMTOWTDI when it comes to CSV. These things were all done to death by the time we were probably even born. Hindsight is 20/20. We can see it so clearly because of those who have beaten the dead horse before us. It's also fun to work it out ourselves so we often fall into the trap of repeating their mistakes. If you can avoid it you're better off avoiding CSV altogether. There's no particular reason that it couldn't or can't be done reliably, but the historical failure behind it curses it as a format for all eternity. "CSV" is not well-defined and never will be for historical purposes. If you can't use something else then try to use an existing library abstraction to save yourself the trouble of repeating bugs. -- acc.js | al4anim - Allegro 4 Animation library | Allegro 5 VS/NuGet Guide | Allegro.cc Mockup | Allegro.cc <code> Tag | Allegro 4 Timer Example (w/ Semaphores) | Allegro 5 "Winpkg" (MSVC readme) | Bambot | Blog | C++ STL Container Flowchart | Castopulence Software | Check Return Values | Derail? | Is This A Discussion? Flow Chart | Filesystem Hierarchy Standard | Clean Code Talks - Global State and Singletons | How To Use Header Files | GNU/Linux (Debian, Fedora, Gentoo) | rot (rot13, rot47, rotN) | Streaming |
|
Peter Hull
Member #1,136
March 2001
|
bamccaig said: What happens when the data itself contains embedded "records"? Now you need to embed them within records recursively! I believe this family of 'delimited ASCII' formats were only ever intended to represent tabular text - typed and/or structured data is really outside the remit. Anyway, you're right, we are where we are, just like CRLF vs LF and just like '\' vs '/' - decisions made a long time ago still cause us pain today.
|
|
bamccaig
Member #7,536
July 2006
|
Peter Hull said: I believe this family of 'delimited ASCII' formats were only ever intended to represent tabular text - typed and/or structured data is really outside the remit. Sure, you can set arbitrary limitations on the format to make it work without hiccups, but then in its initial form it was probably not valid to have embedded commas or newlines within fields either. There was no problem using these characters as syntax. The problem with using custom code points is that typing them is difficult, and one of the advantages to CSV is that it is generally human-readable and human-writable. Using custom code points that are difficult to type or that maybe don't have recognizable glyphs (or aren't even printing characters?) would make the format less accessible. Fortunately there are a plethora of alternative formats that are standardized and can support any kind of data you throw at them. -- acc.js | al4anim - Allegro 4 Animation library | Allegro 5 VS/NuGet Guide | Allegro.cc Mockup | Allegro.cc <code> Tag | Allegro 4 Timer Example (w/ Semaphores) | Allegro 5 "Winpkg" (MSVC readme) | Bambot | Blog | C++ STL Container Flowchart | Castopulence Software | Check Return Values | Derail? | Is This A Discussion? Flow Chart | Filesystem Hierarchy Standard | Clean Code Talks - Global State and Singletons | How To Use Header Files | GNU/Linux (Debian, Fedora, Gentoo) | rot (rot13, rot47, rotN) | Streaming |
|
Chris Katko
Member #1,881
January 2002
|
bamccaig said: difficult to type or that maybe don't have recognizable glyphs (or aren't even printing characters?) would make the format less accessible. Anyone running CSV as a developer should at the bare minimum be running a text editor that can show non-printable characters, such as Notepad2/Notepad++. Even if you don't use them as delimiters, some moron, writing some terrible e-mail program (Outlook?), is going to send non-printable ASCII characters in some malformed XML/HTML e-mail and it's going to infuriate you when it crashes. I ended up having to run a regular expression in Notepad++ to match and remove all non-printable characters because Microsoft Dynamics would fail out the second it tried to read it. -----sig: |
|
|
1
2
|




 It's mostly dealing with terrible tool chains full of bugs that refuse to work together.
It's mostly dealing with terrible tool chains full of bugs that refuse to work together. Albeit, something of this nature is less of a language competition and more of a library competition. I started learning Haskell, and it was actually quite enlightening, but I got distracted and haven't returned. Wrapping your head around coding with monads takes some effort...
Albeit, something of this nature is less of a language competition and more of a library competition. I started learning Haskell, and it was actually quite enlightening, but I got distracted and haven't returned. Wrapping your head around coding with monads takes some effort...
 There's no use crying over spilled fields.
There's no use crying over spilled fields.
{kind=link}
{kind=link}