|
|
|
This thread is locked; no one can reply to it.

|
1
2
|
| Discussion Thursdays? |
|
Sol Blast
Member #9,655
April 2008
 |
Good Morning! (From Ireland anyway.) I've had this idea for a thread for a while, ignore it if you don't think it's a good one. Personally I think it'd be a great way for everyone to expand their knowledge and learn about things it never occurred to them to learn about before. I'll get the ball rolling for this week by suggesting we discuss... Bitwise Operators? I'll leave it to the first proper contributor to choose the definite topic if they have a better idea though. |
|
Thomas Harte
Member #33
April 2000
 |
Ummm, not much to say really... All numbers are stored as a binary code, i.e. in base 2. If you bitwise OR two bits then the result is set iff either of the two input bits were set. If you bitwise AND two bits then the result is set iff both of the input bits were set. If you bitwise EXCLUSIVE-OR two bits then the result is set iff exactly one of the input bits was set. The bitwise NOT of a single bit is that bit inverted. The effect of carrying out a bitwise operation using integers is that the bitwise operation is carried out on each digit separately. The C operators are '|' for OR, '&' for AND, '^' for EXCLUSIVE-OR and '~' for NOT. |, & and ^ are binary operators, ~ is a unary operator. Bitwise operations are often seen in C/C++ programs to represent flags. For example:
Another common construction is this: if(NewVar^OldVar&NewVar&FLAG_1) { // executes only if flag 1 is set in NewVar but not in OldVar } OldVar = NewVar; Which is fairly easy to understand. The EXCLUSIVE OR effectively produces a number with a bit set everywhere a bit has changed between OldVar and NewVar, the AND with NewVar keeps only those bits that have changed and are set in NewVar, and the AND with FLAG_1 throws away all those bits that aren't flag 1. Then the usual C rule of 'execute if expression is non-zero' takes the code into the if statement. Ummm, I guess you also sometimes see: a ^= b; b ^= a; a ^= b; To do an in-place swap of the values of a and b. That works because binary operators are commutative and associative - b ^ a ^ b = a ^ b ^ b = a ^ (b ^ b) = a ^ 0 = a. And in that case we go from:
So at the end, a = a^b^b^a^b = (a^a) ^ (b^b) ^ b = 0 ^ 0 ^ b = b, and b = b ^ a ^ b = b ^ b ^ a = 0 ^ a = a. It's rare that you need to do bitwise stuff other than to communicate with hardware at the lowest level, but lots of programmers with lower level experience put a lot of it around because it just matches how they think about things. Probably lots more to say, but with these things it's all just directly consequential from the definition... EDIT: P.s. neat idea, especially if someone is going to start transposing this stuff into the wiki? [My site] [Tetrominoes] |
|
alethiophile
Member #9,349
December 2007
 |
The first ten or so times I saw the 'if and only if' construction 'iff', I thought it was an unusually persistent typo. The main time I used bitwise operators was when trying to pack/unpack bytes from a long; I ended up using a union eventually. -- |
|
Evert
Member #794
November 2000
 |
I use bitwise operators a lot to check/set/clear bit-encoded flags, as TH stated. I tend to use hexadecimal notation rather than decimal when defining flags, mainly because it's more closely linked to the lower level bitwise encoding. My main source of frustration is trying to use bit flags in FORTRAN. Let's just say it wasn't designed with bitwise operators in mind; it uses functions to provide similar functionality: BTEST, DSHIFTL, DSHIFTR, IAND, IBCHNG, IBCLR, IBITS, IBSET, IEOR, IOR, ISHA, ISHC, ISHFT, ISHFTC, ISHL, IXOR, LSHIFT, NOT, RSHIFT , SHIFTL, SHIFTR. |
|
SiegeLord
Member #7,827
October 2006
 |
I either use octal (I find it easier to read the hexadecimal for these cases) when defining my flags, or bitwise shifts:
"For in much wisdom is much grief: and he that increases knowledge increases sorrow."-Ecclesiastes 1:18 |
|
bamccaig
Member #7,536
July 2006
 |
SiegeLord said:
enum Flags1 { flag1 = 001, flag2 = 002, flag3 = 004, flag4 = 010, flag5 = 020 };
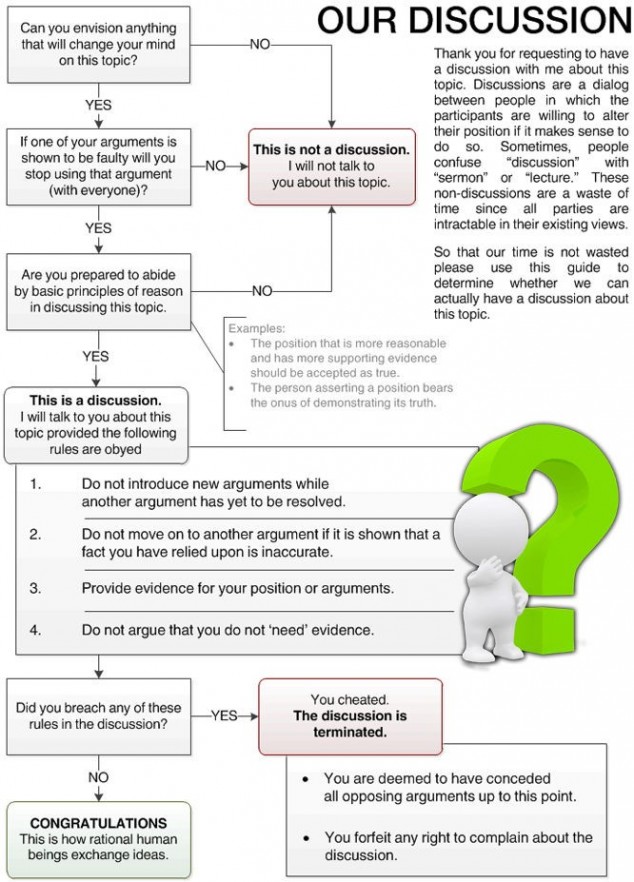
Fixed. -- acc.js | al4anim - Allegro 4 Animation library | Allegro 5 VS/NuGet Guide | Allegro.cc Mockup | Allegro.cc <code> Tag | Allegro 4 Timer Example (w/ Semaphores) | Allegro 5 "Winpkg" (MSVC readme) | Bambot | Blog | C++ STL Container Flowchart | Castopulence Software | Check Return Values | Derail? | Is This A Discussion? Flow Chart | Filesystem Hierarchy Standard | Clean Code Talks - Global State and Singletons | How To Use Header Files | GNU/Linux (Debian, Fedora, Gentoo) | rot (rot13, rot47, rotN) | Streaming |
|
Peter Wang
Member #23
April 2000
|
What he was thinking in the first place: enum Flags1 { flag1 = 0x1, flag2 = 0x2, flag3 = 0x4, flag4 = 0x8, flag5 = 0x10 };
|
|
SiegeLord
Member #7,827
October 2006
|
nvm, need more sleep. "For in much wisdom is much grief: and he that increases knowledge increases sorrow."-Ecclesiastes 1:18 |
|
Todd Cope
Member #998
November 2000
 |
Quote: The bitwise NOT of a single bit is that bit inverted. How do you perform this in C? Can I just do: flags ~= MYFLAG; I need to toggle bits from time to time and have been using flags ^= MYFLAG; // edited, I put ~ by mistake but I don't really know if that is the correct way to do it. |
|
Evert
Member #794
November 2000
|
Quote: Can I just do: flags ~= MYFLAG; I need to toggle bits from time to time and have been using flags ~= MYFLAG; but I don't really know if that is the correct way to do it.
Only if you know MYFLAG is set. |
|
Todd Cope
Member #998
November 2000
|
Quote: The proper way would be flags &= ~MYFLAG. Will that toggle MYFLAG on if it is not already on? Seems to me like it would only turn it off if it is on. |
|
Edgar Reynaldo
Major Reynaldo
May 2007
 |
To flip specific bits of a number , Bitwise XOR the number with a number that has only the bits you want to flip set to 1. // const int X = 1; const int Y = 2; const int Z = 4; int a = X | Z; int b = a ^ Y; int c = X | Y | Z; if (c == b) {XOR_1_Flips_Bits();} //
1 XOR 0 is 1 because they are different 0 XOR 1 is 1 because they are different My Website! | EAGLE GUI Library Demos | My Deviant Art Gallery | Spiraloid Preview | A4 FontMaker | Skyline! (Missile Defense) Eagle and Allegro 5 binaries | Older Allegro 4 and 5 binaries | Allegro 5 compile guide |
|
Evert
Member #794
November 2000
|
Sorry, I got confused. To turn bits off (which I though was what you wanted to know), do what I said. To toggle them, logical xor is indeed the correct way to do it. |
|
Edgar Reynaldo
Major Reynaldo
May 2007
|
I made a mistake in the code I posted - I used binary NOT (~) instead of XOR (^), and I compared a to c when I meant to compare b to c. It is corrected now. On a different note, I thought XOR variable swapping was so cool when I first saw it, but it performs much more slowly than using temporary variables to swap the values. TestIntSwapSpeed.cpp
Profiling results : Unoptimized mingw32-g++ -Wall -pg -o TestIntSwapSpeed.exe TestIntSwapSpeed.cpp Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls s/call s/call name 31.05 3.94 3.94 500000000 0.00 0.00 IntXorSwap(int&, int&) 24.27 7.02 3.08 500000000 0.00 0.00 IntTempSwap(int&, int&) 22.62 9.89 2.87 1 2.87 5.95 TestTempSwap(int, int, unsigned int) 22.06 12.69 2.80 1 2.80 6.74 TestXorSwap(int, int, unsigned int) Optimized with -O2 mingw32-g++ -Wall -pg -O2 -o TestIntSwapSpeed.exe TestIntSwapSpeed.cpp Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls s/call s/call name 49.13 3.10 3.10 500000000 0.00 0.00 IntXorSwap(int&, int&) 27.42 4.83 1.73 500000000 0.00 0.00 IntTempSwap(int&, int&) 11.89 5.58 0.75 1 0.75 2.48 TestTempSwap(int, int, unsigned int) 11.57 6.31 0.73 1 0.73 3.83 TestXorSwap(int, int, unsigned int)
So unoptimized, 500,000,000 swaps using XOR took 3.94 seconds and using a temp variable took 3.08 seconds. Percentage wise, unoptimized XOR swapping takes ~128% as much time as temp swapping, and optimized XOR swapping takes 180% as much time as temp swapping for integers. Here's the assembly code MinGW produces when there's no profiling : Unoptimized : mingw32-g++ -Wall -S -o TestIntSwapSpeed_asm.txt TestIntSwapSpeed.cpp
Optimized : mingw32-g++ -Wall -O2 -S -o TestIntSwapSpeed_O2_asm.txt TestIntSwapSpeed.cpp
Assembly operation tallies : Version pushl popl movl xorl subl leave total ----------------------------------------------------------------------------------- Unoptimized XOR swap (__Z10IntXorSwapRiS_) 1 1 16 3 0 0 21 Temp swap (__Z11IntTempSwapRiS_) 1 0 11 0 1 1 14 Optimized XOR swap (__Z10IntXorSwapRiS_) 1 1 6 3 0 0 11 Temp swap (__Z11IntTempSwapRiS_) 2 2 7 0 0 0 11 The xorl operation must be pretty slow if both optimized versions take the same number of operations but the XOR swap takes 9/5 as long to complete. My Website! | EAGLE GUI Library Demos | My Deviant Art Gallery | Spiraloid Preview | A4 FontMaker | Skyline! (Missile Defense) Eagle and Allegro 5 binaries | Older Allegro 4 and 5 binaries | Allegro 5 compile guide |
|
anonymous
Member #8025
November 2006
|
The xor-swap is also missing an identity check (it assumes it has two variables for storage and won't work if A and B refer to the same variable). void IntXorSwap(int& A , int& B) { if (&A != &B) { A ^= B; B ^= A; A ^= B; } }
|
|
Edgar Reynaldo
Major Reynaldo
May 2007
|
You're right. The XOR method will be even slower then. Unoptimized : mingw32-g++ -Wall -pg -o TestIntSwapSpeed.exe TestIntSwapSpeed.cpp Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls s/call s/call name 34.43 4.61 4.61 500000000 0.00 0.00 IntXorSwap(int&, int&) 23.30 7.73 3.12 500000000 0.00 0.00 IntTempSwap(int&, int&) 22.03 10.68 2.95 1 2.95 7.56 TestXorSwap(int, int, unsigned int) 20.24 13.39 2.71 1 2.71 5.83 TestTempSwap(int, int, unsigned int) Optimized with -O2 mingw32-g++ -Wall -O2 -pg -o TestIntSwapSpeed.exe TestIntSwapSpeed.cpp Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls s/call s/call name 53.09 2.92 2.92 500000000 0.00 0.00 IntXorSwap(int&, int&) 26.18 4.36 1.44 500000000 0.00 0.00 IntTempSwap(int&, int&) 13.45 5.10 0.74 1 0.74 2.18 TestTempSwap(int, int, unsigned int) 7.27 5.50 0.40 1 0.40 3.32 TestXorSwap(int, int, unsigned int)
Execution time ratio for updated XOR method to temp method : Assembly output
Tallies : Version pushl popl cmpl movl xorl je total ----------------------------------------------------------------------------------- Unoptimized XOR swap (__Z10IntXorSwapRiS_) 1 1 1 17 3 1 24 Optimized XOR swap (__Z10IntXorSwapRiS_) 1 1 1 6 3 1 13 It's interesting to see that the -O2 version was able to trim off 11 movl operations. Is that the difference between keeping the data in the registers and checking it from memory? My Website! | EAGLE GUI Library Demos | My Deviant Art Gallery | Spiraloid Preview | A4 FontMaker | Skyline! (Missile Defense) Eagle and Allegro 5 binaries | Older Allegro 4 and 5 binaries | Allegro 5 compile guide |
|
Thomas Harte
Member #33
April 2000
|
Quote: On a different note, I thought XOR variable swapping was so cool when I first saw it, but it performs much more slowly than using temporary variables to swap the values. Yep, it long ago stopped being a fast trick and is now just something worth mentioning to ensure that everyone's on the same page with respect to the commutative and associative properties of bitwise operators. You will sometimes still see people using it, but as with a lot of things, it's mostly personal taste and probably marks them out as an older programmer; on something like a z80 where xors cost exactly the same as inter-register loads, three xors superficially costs the same in cycles but saves a valuable register. On modern x86 I think we all know that the 'registers' aren't actually registers but rather merely a shorthand to describe how subsequent values relate to earlier ones and the bottlenecks that actually cost are completely unrelated to how quickly you can swap values for any application that anybody actually cares about. [My site] [Tetrominoes] |
|
Evert
Member #794
November 2000
|
How about "a^=a" versus "a=0"? Is the former still faster? I can't imagine it is. Quote: as with a lot of things, it's mostly personal taste and probably marks them out as an older programmer A preference for obfuscated code? Hmm... Quote: On modern x86 I think we all know that the 'registers' aren't actually registers but rather merely a shorthand to describe how subsequent values relate to earlier ones I didn't know! Do you have a link where this is discussed in a bit more detail? |
|
Thomas Harte
Member #33
April 2000
|
Quote: I didn't know! Do you have a link where this is discussed in a bit more detail? Ummm, I was really just making oblique reference to the combination of feeding multiple simultaneous pipelines through data dependency calculation and, I guess, a little bit to caching. So if a CPU spots that registers A, B and C are all being used to do one calculation then D, E and F are used to do another that doesn't depend on the results of the A, B, C calculation then it can often do the A, B and C calculation simultaneously to the D, E and F calculation and not have to worry about the two strands being in synchronisation until something tries to combine data from both streams. Add that to processors like the Pentium Pro on which the first-level cache is operating at the same speed as the CPU and you're really fighting to find a reason that the registers are any more significant than any of the other temporary stores hanging around a chip. Especially where hyperthreading making it less logical to have any sort of primary source of data for calculations. That's before you start discussing how microcoding often maps the x86 instruction set to a more RISCy internal set for the actual processing unit that tends not to have a 1:1 correlation to the named x86 registers. I would therefore distinguish modern registers from the registers of, e.g. the z80, because you can no longer say from looking at your assembly exactly what the state of the named registers is after every instruction. Nowadays you just work on being certain that the state would be reported as a certain thing were you to query it. Which is obviously compatible with the old model but completely changes the field of optimisation. I'm talking generally because I did a general degree way back when and have not subsequently interested myself with specifics. EDIT: Quote: A preference for obfuscated code? Hmm... I don't think it's obfuscated for them. It's just part of the way the brain recognises things; like the way it recognises sentence structures and can fix bits sometimes without you being consciously aware (which is annoying when you're an editor) - they're used to being able to instantly spot that a certain pattern does a certain thing to the extent where 'a ^= b; b ^= a; a ^= b;' just reads instantly as 'swap a and b', not 'a exclusive or with b, store result to a; ...'. I was really just trying to say "you may see this around still, but it's not some sort of magical recipe and don't bother adapting yourself to it now". [My site] [Tetrominoes] |
|
alethiophile
Member #9,349
December 2007
|
I like xor-swap because it's easy to implement as a CPP macro--no passing pointers to a function and no temp variable. The only place I've ever used bitshifts and bitwise things like that is in a very simplistic implementation of ARC4; I'm not doing things like that much anymore. -- |
|
Evert
Member #794
November 2000
|
Quote: I was really just making oblique reference to the combination of feeding multiple simultaneous pipelines through data dependency calculation and, I guess, a little bit to caching. So if a CPU spots that registers A, B and C are all being used to do one calculation then D, E and F are used to do another that doesn't depend on the results of the A, B, C calculation then it can often do the A, B and C calculation simultaneously to the D, E and F calculation and not have to worry about the two strands being in synchronisation until something tries to combine data from both streams. Add that to processors like the Pentium Pro on which the first-level cache is operating at the same speed as the CPU and you're really fighting to find a reason that the registers are any more significant than any of the other temporary stores hanging around a chip. Especially where hyperthreading making it less logical to have any sort of primary source of data for calculations. That's before you start discussing how microcoding often maps the x86 instruction set to a more RISCy internal set for the actual processing unit that tends not to have a 1:1 correlation to the named x86 registers. Ah, yes! That makes sense, actually. I'd never thought about this (in terms of assembler language and processor architecture I never really went much beyond the 486 although I know (knew) a few basic things about the AMD64). Quote: I'm talking generally because I did a general degree way back when and have not subsequently interested myself with specifics.
That's fine, this is exactly the right level of explanation that I was looking for. Thanks. |
|
Vanneto
Member #8,643
May 2007
|
Quote: I like xor-swap because it's easy to implement as a CPP macro--no passing pointers to a function and no temp variable. If you create a function, there are no temp variables (that you see or care about). I personally always use the std functions wherever possible: int a = 1; int b = 2; std::swap (a, b);
In capitalist America bank robs you. |
|
Roy Underthump
Member #10,398
November 2008
 |
Quote: if a CPU spots that registers A, B and C are all being used to do one calculation then D, E and F are used to do another that doesn't depend on the results of the A, B, C calculation then it can often do the A, B and C calculation simultaneously to the D, E and F calculation Registers themselves have "shadow copies" (up to 128 for eax) so that if your lame compiler uses some particular register to do one set of operations, then uses it immediately afterward to do some other independant set of ops, it can use a shadow register to do the second set of ops before the first set has finished. I love America -- I love the rights we used to have |
|
alethiophile
Member #9,349
December 2007
|
How does that std::swap work? It shouldn't be able to swap variables in the calling context without getting pointers to them, unless C++ is much weirder than I thought. -- |
|
Vanneto
Member #8,643
May 2007
|
Ever heard of references? void change (int &var) { var++; } int main () { int var = 1; change(var); // var is now 2! \o/ }
In capitalist America bank robs you. |
|
|
1
2
|
 .
.


{kind=link}
{kind=link}